Nên dành bao nhiêu phần trăm ngân sách cho SEO?
Chi tiêu cho SEO bây giờ là một khoản đầu tư vào doanh thu trong tương lai của doanh nghiệp bạn. Tìm hiểu các yếu tố





Google chia sẻ 6 mẹo làm nổi bật kết quả tìm kiếm của các website E-commerce
Mới đây Google đã xuất bản một video mới cung cấp 6 mẹo về cách giúp cho các trang website thương mại điện tử trở

Sự khác biệt giữa báo cáo Core Web Vitals của Search Console và thông tin trên PageSpeed Insights
Tiếp tục với chủ đề “Những rủi ro khi xóa tệp Disavow“, một chủ đề được quan tâm khác cũng được John Mueller giải thích

5 TIP để cải thiện chiến lược nội dung của bạn
Content đóng một vai trò quan trọng trong mọi chiến dịch marketing. Dưới đây là một số cách có thể giúp bạn cải thiện chiến

Có bất kỳ rủi ro nào khi xóa tệp Disavow?
Mới đây trong 1 video hỏi đáp trên kênh youtube Google Search Central, Google giải thích lý do tại sao các trang web bình thường

15 công cụ quản lý dự án dành cho các Chuyên gia SEO
Luôn dẫn đầu tất cả các chiến dịch SEO của bạn có thể rất khó khăn. Danh sách các công cụ quản lý dự án

Google cập nhật hướng dẫn cho các trang biến thể sản phẩm và kết quả nhiều định dạng
Google đã cập nhật trang hỗ trợ kết quả nhiều định dạng về sản phẩm để thêm thông tin chi tiết về cách có thể sử

Googlebot sẽ thu thập thông tin và lập chỉ mục 15MB nội dung đầu tiên trên mỗi trang
Mới đây Google đã cập nhật nội dung trong tài liệu hỗ trợ của mình trên Googlebot, trong đó họ đề cập đến để đến

Google Marketing Live 2022 có gì mới?
Dưới đây là bản tóm tắt tất cả các tin tức về Quảng cáo và tiếp thị từ sự kiện hàng năm của Google, bao

Google Ads Update Trang Thử Nghiệm mới
Google Ads sẽ ra mắt trang Thử nghiệm cập nhật. Trong trang Thử nghiệm mới, nhà quảng cáo không còn phải tạo bản nháp chiến

8 thay đổi đáng chú ý của quảng cáo Google Ads 2021
2021 là một năm có nhiều sự thay đổi trong quảng cáo Google Ads. Chúng ta hãy cùng điểm lại những sự kiện đó nhé!

Giải thích đơn giản về Domain Authority cho những người không phải dân SEO
Domain Authority là gì? Bài viết này sẽ hướng dẫn bạn cách truyền tải thông tin nếu bạn đang phải giải thích về tầm quan
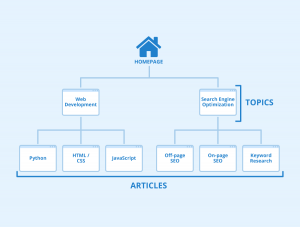
Website Structure là gì? 12 cách xây dựng cấu trúc trang web tối ưu chuẩn SEO nhất
Website Structure là gì? Xây dựng Website Structure là một trong những điều cơ bản nhưng lại quan trọng nhất về kỹ thuật SEO. Tuy
Semantic Search là gì? Nó ảnh hưởng thế nào đến SEO?
Semantic Search là gì? Nó ảnh hưởng thế nào đến SEO? Semantic Search là gì? Có bao giờ bạn nhận ra rằng, Google có thể
[Google Update] Chiến dịch Performance Max campaigns – chiến dịch Hiệu suất Tối đa Google Ads
Chiến dịch Performance Max campaigns là gì? Performance Max campaigns hay còn gọi là chiến dịch Hiệu suất Tối đa là một loại chiến dịch


Email marketing là gì? 5 bước triển khai email marketing hiệu quả
Tại thời điểm hiện nay, với sự xuất hiện của các kênh marketing mới và mang hiệu quả tốt hơn nhiều so với hình thứ